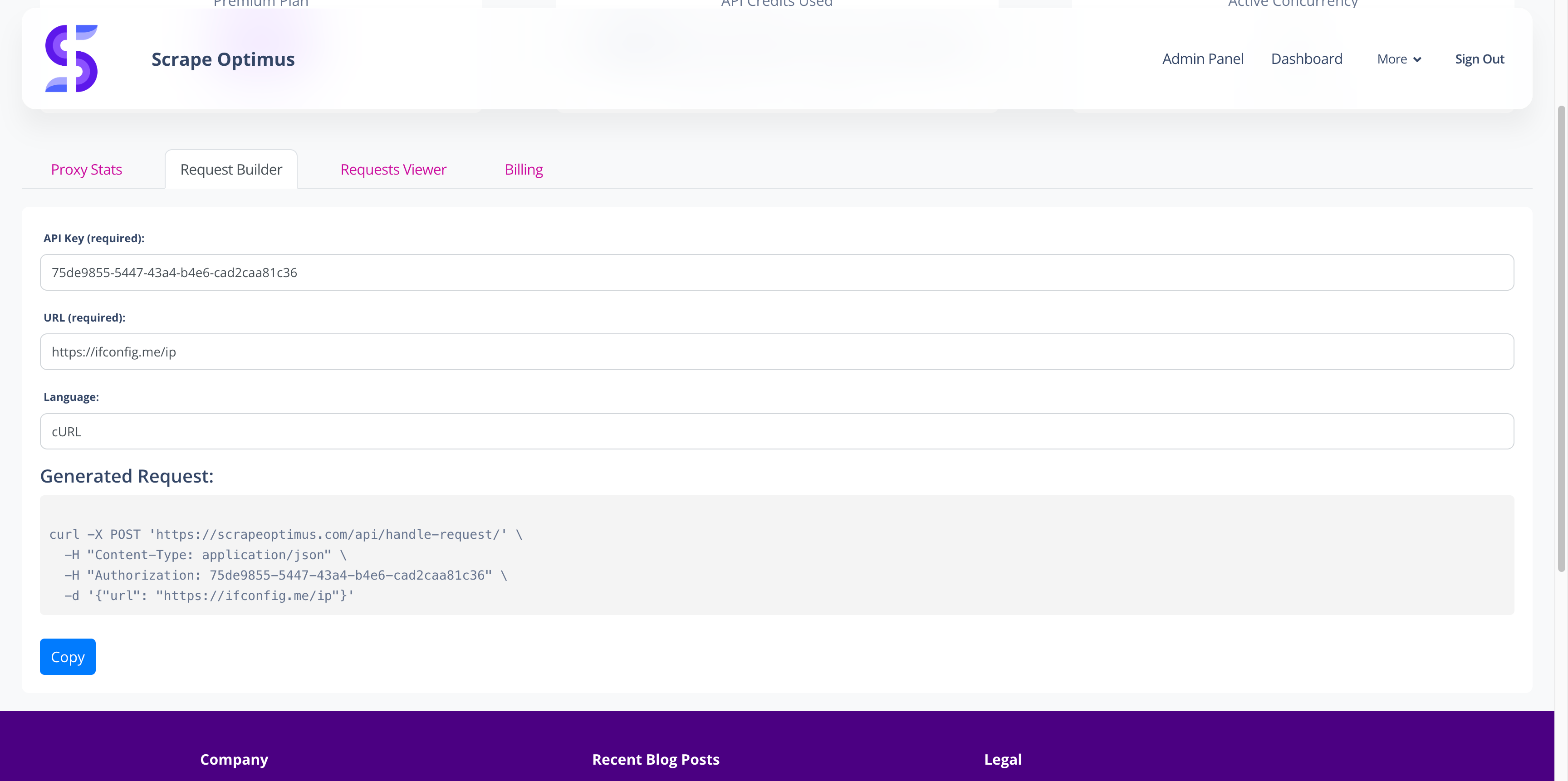
Scrape Optimus: A Versatile Web Scraping Solution
Welcome to Scrape Optimus, a comprehensive web scraping platform designed to simplify data extraction processes and enhance efficiency. Scrape Optimus provides a complete suite of tools for diverse scraping needs, with powerful features that cater to both small projects and large-scale data collection.
Production
Available at: https://scrapeoptimus.com
Feel free to register for a free account and try it.
Key Features
- Proxy Aggregator: Integrate with over 200 proxy providers through a single API to ensure reliable, scalable, and efficient data collection.
- Job Scheduling: Automate your web scraping tasks by connecting to Scrape Optimus's scheduler, effectively managing scraping jobs with minimal intervention.
- Monitoring & Alerts: Track your scraping jobs in real-time, receive alerts, and manage potential issues from a centralized dashboard.
- Custom Solutions: Tailored web scraping solutions for specific requirements, providing flexibility for unique project needs.
- Dockerized Deployment: Fully containerized for easy deployment and scalability.
- Kubernetes Support: Kubernetes-native support to help scale your web scraping projects seamlessly.
- MailJet Integration: Reliable email service integration for sending notifications.
- S3 Bucket Integration: Store scraped data securely using AWS S3 or MinIO storage solutions.
- Affiliate Program: Coming soon, Scrape Optimus will introduce an affiliate program to expand the reach of our services.
- AI Scraping: Planned for future updates, leveraging AI to make scraping smarter and more adaptable to changing websites.
Learning and Technologies Used
Transition to Asynchronous Operations
Initially, our project used synchronous APIs, which caused the server to hang under heavy loads. To address this issue, we transitioned our project to use asynchronous APIs, enabling non-blocking operations and significantly improving the handling of multiple simultaneous requests.
Optimized Database Interaction
We reduced the load on our PostgreSQL database by minimizing the number of interactions during API calls. For example, counter management tasks were moved to Redis to avoid frequent database access. Redis also plays a key role in ensuring concurrency control, with Redis locks used to manage resource access effectively.
Kafka for High Throughput Logging
We integrated Kafka for logging API requests due to its ability to handle high throughput with low latency. This helps us maintain efficient, scalable logging without putting a strain on the main application infrastructure.
Efficient Batch Processing with Celery
We use Celery jobs to periodically dump counter data and logs into the database. Instead of inserting log records individually, the logs are batch-inserted, which reduces the database load and enhances performance.
VPN to Proxy Conversion
We have developed a technology using OpenVPN that converts VPNs into proxies, providing a unique and scalable rotating proxy mechanism. This ensures users always receive different IP addresses when scraping, thereby enhancing anonymity and efficiency. In the future, we plan to partner with more proxy providers to offer the best possible solution.
Monitoring and Alerts for Scrapy Servers
With the Monitoring & Alerts feature, users will soon be able to monitor their Scrapy servers, schedule tasks, and set up alerts for job status and performance metrics. This feature is part of our upcoming updates, designed to provide better control and visibility for users.
RabbitMQ for Email Transactions
Currently, we have integrated RabbitMQ to handle email transactions, which ensures reliable delivery. While transactional emails are yet to be fully integrated, basic account-related notifications are already functional.
Future of AI with Scraping
The introduction of AI in web scraping aims to simplify the process of writing spiders for different websites. Scrapy, which we currently use for scraping career pages of various companies, often requires manually writing spiders for each unique website, which is time-consuming. Our goal is to leverage AI to automate this process—enabling the AI to analyze HTML tags and structures, understand page layouts, and generate spiders autonomously. This will save significant time and effort while increasing scalability.
Payment Gateway Integration
To accommodate customers globally, we have integrated PayPal for international transactions and Razorpay for Indian customers. The choice of payment gateway is determined dynamically based on the customer's location and billing address, ensuring a seamless checkout experience.
Scrape Optimus is designed to make web scraping efficient, scalable, and user-friendly, offering a powerful tool for extracting valuable insights from the web while optimizing every aspect of the process for performance and reliability. Proudly built completely by Arpan Sahu.
Tech Stack